![]()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-50, 50, 400)
y = np.linspace(-50, 50, 400)
X, Y = np.meshgrid(x, y)
Z = 1/20*X**2 + Y**2
plt.contour(X, Y, Z, levels=[1, 5, 10, 20, 40], colors='b')
plt.xlabel('x')
plt.ylabel('y')
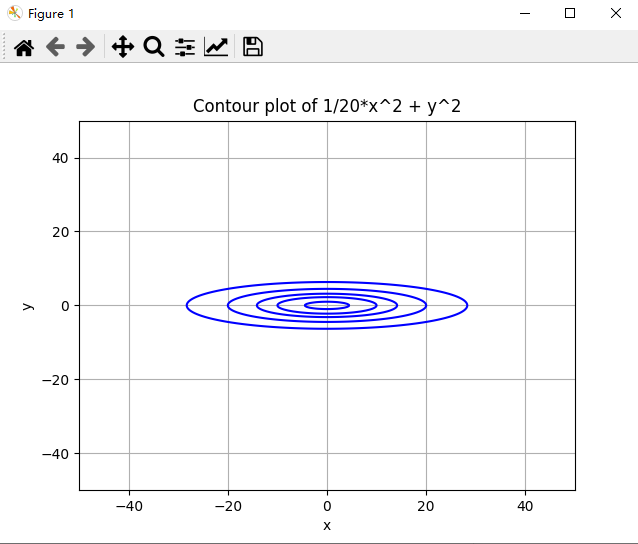
plt.title('Contour plot of 1/20*x^2 + y^2')
plt.grid(True)
plt.show()
|
这段代码是使用Python语言编写的,其目的是通过matplotlib库绘制函数 1/20*x^2 + y^2 在x和y范围为[-50, 50]内的等高线图。下面是详细解释:
import numpy as np:导入numpy库,并简写为np。Numpy是Python中用于处理数组和矩阵的库,常用于数值计算。
import matplotlib.pyplot as plt:导入matplotlib.pyplot库,并简写为plt。Matplotlib是Python中一个常用的绘图库,可以创建各种静态、动态、交互式的图表。
x = np.linspace(-50, 50, 400):使用numpy的linspace函数,在-50到50之间创建一个包含400个点的等间距数列,赋值给变量x。
y = np.linspace(-50, 50, 400):与上一行类似,创建另一个在-50到50之间的包含400个点的等间距数列,赋值给变量y。
X, Y = np.meshgrid(x, y):使用numpy的meshgrid函数,根据x和y数组生成一个二维的网格坐标系。X和Y是二维数组,其中X的每个元素表示相应点的x坐标,Y的每个元素表示相应点的y坐标。
Z = 1/20*X**2 + Y**2:定义一个二维数组Z,用于存储根据公式 1/20*x^2 + y^2 计算出的每个网格点的z值。
plt.contour(X, Y, Z, levels=[1, 5, 10, 20, 40], colors='b'):使用matplotlib的contour函数绘制等高线图。X和Y是网格点的坐标,Z是每个网格点的高度。levels 参数定义了绘制的等高线的高度值,本例中为[1, 5, 10, 20, 40]。colors 参数定义了等高线的颜色,本例中为蓝色(’b’)。
plt.xlabel('x'):为图表的x轴添加标签,标签内容为 ‘x’。
plt.ylabel('y'):为图表的y轴添加标签,标签内容为 ‘y’。
plt.title('Contour plot of 1/20*x^2 + y^2'):为图表添加标题,标题内容为 ‘Contour plot of 1/20*x^2 + y^2’。
plt.grid(True):添加网格线。参数True表示显示网格线。
plt.show():显示图表。这会打开一个窗口展示刚刚绘制的等高线图。
总的来说,这段代码使用numpy和matplotlib库,绘制了函数1/20*x^2 + y^2在x和y范围为[-50, 50]内的等高线图。通过调整参数,我们可以改变图像的分辨率,等高线的值以及其他可视化属性。此图形有助于我们理解函数在二维空间中的形状。特别是,通过这种可视化方式,我们可以很容易地看到函数的高度变化以及它在不同区域的曲率。
在执行这段代码时,你需要确保你的Python环境中已经安装了numpy和matplotlib库。如果没有安装,可以通过pip工具来安装:
1
| pip install numpy matplotlib
|
然后,你可以将这段代码保存为一个.py文件,或在Jupyter Notebook中运行它。如果一切正常,你应该能看到一个展示等高线的窗口。在这个图中,蓝色的线表示函数在不同高度值(1, 5, 10, 20, 40)的轮廓。你还会注意到x轴和y轴都有标签,图表中包含网格线,以及标题说明了图的内容。
这种可视化方法在学习和理解多变量函数时是非常有用的,它可以帮助我们了解函数的形状、极值点以及其他重要特性。